{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"# *Chapter 10*
High-Performance Hardware & Parallel Computers \n",
"\n",
"| | | |\n",
"|:---:|:---:|:---:|\n",
"| |[From **COMPUTATIONAL PHYSICS**, 3rd Ed, 2015](http://physics.oregonstate.edu/~rubin/Books/CPbook/index.html)
RH Landau, MJ Paez, and CC Bordeianu (deceased)
Copyrights:
[Wiley-VCH, Berlin;](http://www.wiley-vch.de/publish/en/books/ISBN3-527-41315-4/) and [Wiley & Sons, New York](http://www.wiley.com/WileyCDA/WileyTitle/productCd-3527413154.html)
R Landau, Oregon State Unv,
MJ Paez, Univ Antioquia,
C Bordeianu, Univ Bucharest, 2015.
Support by National Science Foundation.||\n",
"\n",
"**10 High-Performance Hardware & Parallel Computers**
\n",
"[10.1 High-Performance Computers](#10.1)
\n",
"[10.2 Memory Hierarchy](#10.2)
\n",
"[10.3 The Central Processing Unit](#10.3)
\n",
"[10.4 CPU Design: Reduced Instruction Set Processors](#10.4)
\n",
"[10.5 CPU Design: Multiple-Core Processors](#10.5)
\n",
"[10.6 CPU Design: Vector Processors](#10.6)
\n",
"[10.7 Introduction to Parallel Computing](#10.7)
\n",
"[10.8 Parallel Semantics (Theory)](#10.8)
\n",
"[10.9 Distributed Memory Programming](#10.9)
\n",
"[10.10 Parallel Performance](#10.10)
\n",
"[10.10.1 Communication Overhead](#10.10.1)
\n",
"[10.11 Parallelization Strategies](#10.11)
\n",
"[10.12 Practical Aspects of MIMD Message Passing](#10.12)
\n",
" [10.12.1 High-Level View of Message Passing](#10.12.1)
\n",
" [10.12.2 Message Passing Example & Exercise](#10.12.2)
\n",
"[10.13 Scalability](#10.13)
\n",
" 10.13.1 Scalability Exercises](#10.13.1)
\n",
"[10.14 Data Parallelism and Domain Decomposition](#10.1)
\n",
" 10.14.1 Domain Decomposition Exercises](#10.14)
\n",
"[10.15 The IBM Blue Gene Supercomputers](#10.15)
\n",
"[10.16 Exascale Computing via Multinode-Multicore-GPU’s](#10.16)
\n",
" \n",
"*This chapter discusses a number of topics associated with\n",
"high-performance computing (HPC) and parallel computing. Although this\n",
"may sound like something only specialists should be reading, using\n",
"history as our guide, present HPC hardware and software will be desktop\n",
"in less than a decade, and so you may as well learn these things now. We\n",
"start with a discussion of a high-performance computer’s memory and\n",
"central processor design, and then examine various general aspects of\n",
"parallel computing. [Chapter 11](CP11.ipynb) goes on to discuss some\n",
"practical programming aspects of HPC and parallel computing. HPC is a\n",
"broad subject, and our presentation is brief and given from a\n",
"practitioner’s point of view. The text \\[[Quinn(04))](BiblioLinked.html#quinn)\\] surveys parallel\n",
"computing and MPI from a computer science point of view. Other\n",
"references on parallel computing include \\[[van de Velde(94))](BiblioLinked.html#van2), [Fox(94))](BiblioLinked.html#fox2),\n",
"[Pancake(96))](BiblioLinked.html#cherri)\\].*\n",
"\n",
"** This Chapter’s Lecture, Slide Web Links, Applets & Animations**\n",
"\n",
"| | |\n",
"|---|---|\n",
"|[All Lectures](http://physics.oregonstate.edu/~rubin/Books/CPbook/eBook/Lectures/index.html)|[](http://physics.oregonstate.edu/~rubin/Books/CPbook/eBook/Lectures/index.html)|\n",
"\n",
"| *Lecture (Flash)*| *Slides* | *Sections*|*Lecture (Flash)*| *Slides* | *Sections*| \n",
"|- - -|:- - -:|:- - -:|- - -|:- - -:|:- - -:|\n",
"|[High Performance Computing](http://physics.oregonstate.edu/~rubin/Books/CPbook/eBook/Lectures/Modules/Hardware/Hardware.html)|[pdf](http://physics.oregonstate.edu/~rubin/Books/CPbook/eBook/Lectures/Slides/Slides_NoAnimate_pdf/HPC1.pdf)|14.1-.4|[HPC Hardware](http://physics.oregonstate.edu/~rubin/Books/CPbook/eBook/Lectures/Modules/HardwareII/HardwareII.html)|[pdf](http://physics.oregonstate.edu/~rubin/Books/CPbook/eBook/Lectures/Slides/Slides_NoAnimate_pdf/HPC2.pdf)|14.4-.6, 14.13|\n",
"|[HPC Exercises](http://physics.oregonstate.edu/~rubin/Books/CPbook/eBook/Lectures/Modules/HPCexercis/HPCexercise.html)|[pdf](http://physics.oregonstate.edu/~rubin/Books/CPbook/eBook/Lectures/Slides/Slides_NoAnimate_pdf/HPCexer1.pdf)|14.14-.15 |[HPC Exercises II](http://physics.oregonstate.edu/~rubin/Books/CPbook/eBook/Lectures/Modules/HPCexerciseII/HPCexerciseII.html)|[pdf](http://physics.oregonstate.edu/~rubin/Books/CPbook/eBook/Lectures/Slide/Slides_NoAnimate_pdf/HPCexer1.pdf)|14.14-.15|\n",
"|[Parallel Computing](http://physics.oregonstate.edu/~rubin/Books/CPbook/eBook/Lectures/Modules/Parallel/Parallel.html)|[pdf](http://physics.oregonstate.edu/~rubin/Books/CPbook/eBook/Lectures/Slides/Slides_NoAnimate_pdf/Parallel_19July10.pdf)|14.10 |\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 10.1 High-Performance Computers\n",
"\n",
"By definition, supercomputers are the fastest and most powerful\n",
"computers available, and at present the term refers to machines with\n",
"hundreds of thousands of processors. They are the superstars of the\n",
"high-performance class of computers. Personal computers (PC’s) small\n",
"enough in size and cost to be used by an individual, yet powerful enough\n",
"for advanced scientific and engineering applications, can also be\n",
"high-performance computers. We define *high-performance computers* as\n",
"machines with a good balance among the following major elements:\n",
"\n",
"- Multistaged (pipelined) functional units.\n",
"\n",
"- Multiple central processing units (CPU’s).\n",
"\n",
"- Multiple cores.\n",
"\n",
"- Fast central registers.\n",
"\n",
"- Very large, fast memories.\n",
"\n",
"- Very fast communication among functional units.\n",
"\n",
"- Vector, video, or array processors.\n",
"\n",
"- Software that integrates the above effectively and efficiently.\n",
"\n",
"As the simplest example, it makes little sense to have a CPU of\n",
"incredibly high speed coupled to a memory system and software that\n",
"cannot keep up with it.\n",
"\n",
"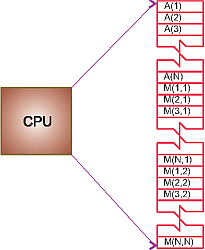\n",
"\n",
"**Figure 10.1** The logical arrangement of\n",
"the CPU and memory showing a Fortran array *A*(*N*) and matrix *M*(*N,\n",
"N*) loaded into memory.\n",
"\n",
"\n",
"## 10.2 Memory Hierarchy\n",
"\n",
"An idealized model of computer architecture is a CPU sequentially\n",
"executing a stream of instructions and reading from a continuous block\n",
"of memory. To illustrate, in Figure 10.1 we have a vector `A[ ]` and an\n",
"array `M[.. , .. ]` loaded in memory and about to be processed. The real\n",
"world is more complicated than this. First, arrays are not stored in 2-D\n",
"blocks, but rather in linear order. For instance, in Python, Java and C\n",
"it is in *row-major* order:\n",
"\n",
"$$\\tag*{10.1}\n",
" M(0,0) M(0,1) M(0,2) M(1,0) M(1,1)\n",
"M(1,2) M(2,0) M(2,1) M(2,2).$$\n",
"\n",
"In Fortran it is in *column-major* order:\n",
"\n",
"$$\\tag*{10.2}\n",
" M(1,1) M(2,1) M(3,1) M(1,2) M(2,2)\n",
"M(3,2) M(1,3) M(2,3) M(3,3),$$\n",
"\n",
"Second, as illustrated in Figures 2 and 3, the values for the matrix\n",
"elements may not even be in the same physical place. Some may be in RAM,\n",
"some on the disk, some in cache, and some in the CPU. To give these\n",
"words more meaning, in Figures 10.3 and 10.2 we show simple models of\n",
"the memory architecture of a high-performance computer. This\n",
"hierarchical arrangement arises from an effort to balance speed and\n",
"cost, with fast, expensive memory supplemented by slow, less expensive\n",
"memory. The memory architecture may include the following elements:\n",
"\n",
"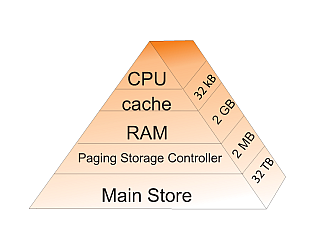\n",
"\n",
"**Figure 10.2** Typical memory hierarchy for a single-processor,\n",
"high-performance computer (B = bytes, K, M, G, T = kilo, mega, giga, tera).\n",
"\n",
"**CPU:**\n",
"Central processing unit, the fastest part of the computer. The CPU\n",
"consists of a number of very-high-speed memory units called *registers*\n",
"containing the *instructions* sent to the hardware to do things like\n",
"fetch, store, and operate on data. There are usually separate registers\n",
"for instructions, addresses, and *operands* (current data) In many cases\n",
"the CPU also contains some specialized parts for accelerating the\n",
"processing of floating-point numbers.\n",
"\n",
"**Cache:**\n",
"A small, very fast bit of memory that holds instructions, addresses, and\n",
"data in their passage between the very fast CPU registers and the\n",
"slower RAM. (Also called a high-speed buffer.) This is seen in the next\n",
"level down the pyramid in Figure 10.2. The main memory is also called\n",
"*dynamic RAM* (DRAM), while the cache is called *static RAM* (SRAM). If\n",
"the cache is used properly, it can greatly reduce the time that the CPU\n",
"waits for data to be fetched from memory.\n",
"\n",
"**Cache lines:**\n",
"The data transferred to and from the cache or CPU are grouped into cache\n",
"or data lines. The time it takes to bring data from memory into the\n",
"cache is called *latency*.\n",
"\n",
"**RAM:**\n",
"Random-access or central memory is in the middle of the memory hierarchy\n",
"in Figure 10.2. RAM is fast because its addresses can be accessed\n",
"directly in random order, and because no mechanical devices are needed\n",
"to read it.\n",
"\n",
"**Pages:**\n",
"Central memory is organized into pages, which are blocks of memory of\n",
"fixed length. The operating system labels and organizes its memory pages\n",
"much like we do the pages of a book; they are numbered and kept track of\n",
"with a *table of contents*. Typical page sizes range from 4 to 16 kB,\n",
"but on supercomputers they may be in the MB range.\n",
"\n",
"**Hard disk:**\n",
"Finally, at the bottom of the memory pyramid is permanent storage on\n",
"magnetic disks or optical devices. Although disks are very slow compared\n",
"to RAM, they can store vast amounts of data and sometimes compensate for\n",
"their slower speeds by using a cache of their own, the *paging storage\n",
"controller*.\n",
"\n",
"**Virtual memory:**\n",
"True to its name, this is a part of memory you will not find in our\n",
"figures because it is *virtual*. It acts like RAM but resides on\n",
"the disk.\n",
"\n",
"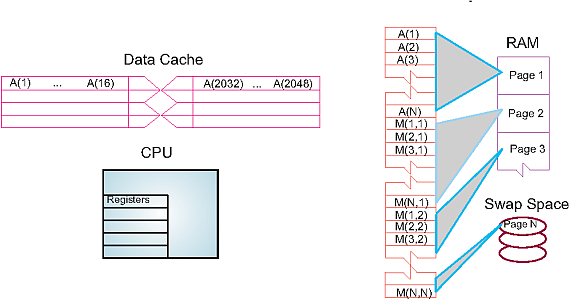\n",
"\n",
"**Figure 10.3** The elements of a computer’s memory architecture in the\n",
"process of handling matrix storage.\n",
"\n",
"When we speak of “fast” and “slow” memory we are using a time scale set\n",
"by the clock in the CPU. To be specific, if your computer has a clock\n",
"speed or cycle time of 1 ns, this means that it could perform a billion\n",
"operations per second, if it could get its hands on the needed data\n",
"quickly enough (typically, more than 10 cycles are needed to execute a\n",
"single instruction). While it usually takes 1 cycle to transfer data\n",
"from the cache to the CPU, the other types of memories are much slower.\n",
"Consequently, you can speed up your program by having all needed data\n",
"available for the CPU when it tries to execute your instructions;\n",
"otherwise the CPU may drop your computation and go on to other chores\n",
"while your data gets transferred from lower memory (we talk more about\n",
"this soon in the discussion of pipelining or cache reuse). Compilers try\n",
"to do this for you, but their success is affected by your programming\n",
"style.\n",
"\n",
"As shown in Figure 10.3, virtual memory permits your program to use more\n",
"pages of memory than can physically fit into RAM at one time. A\n",
"combination of operating system and hardware *maps* this virtual memory\n",
"into pages with typical lengths of 4-16 kB. Pages not currently in use\n",
"are stored in the slower memory on the hard disk and brought into fast\n",
"memory only when needed. The separate memory location for this switching\n",
"is known as *swap space* (Figure 10.5 A).\n",
"\n",
"Observe that when an application accesses the memory location for\n",
"`M[i,j]`, the number of the page of memory holding this address is\n",
"determined by the computer, and the location of `M[i,j]` within this\n",
"page is also determined. A *page fault* occurs if the needed page\n",
"resides on disk rather than in RAM. In this case the entire page must be\n",
"read into memory while the least recently used page in RAM is swapped\n",
"onto the disk. Thanks to virtual memory, it is possible to run programs\n",
"on small computers that otherwise would require larger machines (or\n",
"extensive reprogramming). The price you pay for virtual memory is an\n",
"order-of-magnitude slowdown of your program’s speed when virtual memory\n",
"is actually invoked. But this may be cheap compared to the time you\n",
"would have to spend to rewrite your program so it fits into RAM, or the\n",
"money you would have to spend to buy enough RAM for your problem.\n",
"\n",
"Virtual memory also allows *multitasking*, the simultaneous loading into\n",
"memory of more programs than can physically fit into RAM (Figure 10.5\n",
"A). Although the ensuing switching among applications uses computing\n",
"cycles, by avoiding long waits while an application is loaded into\n",
"memory, multitasking increases the total throughout and permits an\n",
"improved computing environment for users. For example, it is\n",
"multitasking that permits a windowing system, such as Linux, Apple OS or\n",
"Windows, to provide us with multiple windows. Although each window\n",
"application uses a fair amount of memory, only the single application\n",
"currently receiving input must actually reside in memory; the rest are\n",
"*paged out* to disk. This explains why you may notice a slight delay\n",
"when switching to an idle window; the pages for the now-active program\n",
"are being placed into RAM, and the least used application still in\n",
"memory is simultaneously being paged out.\n",
"\n",
"## 10.3 The Central Processing Unit \n",
"\n",
"How does the CPU get to be so fast? Often, it utilizes *prefetching* and\n",
"*pipelining*; that is, it has the ability to prepare for the next\n",
"instruction before the current one has finished. It is like an assembly\n",
"line or a bucket brigade in which the person filling the buckets at one\n",
"end of the line does not wait for each bucket to arrive at the other end\n",
"before filling another bucket. In the same way a processor fetches,\n",
"reads, and decodes an instruction while another instruction is\n",
"executing. Consequently, despite the fact that it may take more than one\n",
"cycle to perform some operations, it is possible for data to be entering\n",
"and leaving the CPU on each cycle. To illustrate, Table 10.1 indicates\n",
"how the operation *c* = (*a* + *b*)/(*d* × *f*) is handled. Here the\n",
"pipelined arithmetic units A1 and A2 are simultaneously doing their jobs\n",
"of fetching and operating on operands, yet arithmetic unit A3 must wait\n",
"for the first two units to complete their tasks before it has something\n",
"to do (during which time the other two sit idle).\n",
"\n",
"**Table 10.1** Computation of *c* = (*a* + *b*)/(*d* × *f*).\n",
"\n",
"|*Arithmetic Unit* | *Step 1*| *Step 2* | *Step 3*| *Step 4*|\n",
"|- - -|- - - |- - -|- - - |- - -|\n",
"| A1 | Fetch *a* |Fetch *b* | Add | - - -|\n",
"| A2 | Fetch *d* |Fetch *f* | Multiply| - - -|\n",
"| A3 | - - - | - - - | - - - |Divide|\n",
"\n",
"## 10.4 CPU Design: Reduced Instruction Set Processors\n",
"\n",
"*Reduced instruction set computer* (RISC) architecture (also called\n",
"*superscalar*) is a design philosophy for CPU’s developed for\n",
"high-performance computers and now used broadly. It increases the\n",
"arithmetic speed of the CPU by decreasing the number of instructions the\n",
"CPU must follow.\n",
"\n",
"with CISC, *complex instruction set computer* architecture. In the late\n",
"1970s, processor designers began to take advantage of *very-large-scale\n",
"integration* (VLSI), which allowed the placement of hundreds of\n",
"thousands of elements on a single CPU chip. Much of the space on these\n",
"early chips was dedicated to *microcode* programs written by chip\n",
"designers and containing machine language instructions that set the\n",
"operating characteristics of the computer. instructions available, and\n",
"many were similar to higher-level programming languages such as *Pascal*\n",
"and *Forth*. The price paid for the large number of complex instructions\n",
"was slow speed, with a typical instruction taking more than 10 clock\n",
"cycles. Furthermore, a 1975 study by Alexander and Wortman of the *XLP*\n",
"compiler of the IBM System/360 showed that about 30 low-level\n",
"instructions accounted for 99% of the use with only 10 of these\n",
"instructions accounting for 80% of the use.\n",
"\n",
"The RISC philosophy is to have just a small number of instructions\n",
"available at the chip level but to have the regular programmer’s high\n",
"level-language, such as Fortran or C, translate them into efficient\n",
"machine instructions for a particular computer’s architecture. This\n",
"simpler scheme is cheaper to design and produce, lets the processor run\n",
"faster, and uses the space saved on the chip by cutting down on\n",
"microcode to increase arithmetic power. Specifically, RISC increases the\n",
"number of internal CPU registers, thus making it possible to obtain\n",
"longer pipelines (cache) for the data flow, a significantly lower\n",
"probability of memory conflict, and some instruction-level parallelism.\n",
"\n",
"The theory behind this philosophy for RISC design is the simple equation\n",
"describing the execution time of a program:\n",
"\n",
"$$\\tag*{10.3} {\\rm CPU\\ time = number\\ of\\ instructions\\ \\times\n",
"cycles/instruction\n",
"\\times cycle\\ time .}$$\n",
"\n",
"Here “CPU time” is the time required by a program, “number of\n",
"instructions” is the total number of machine-level instructions the\n",
"program requires (sometimes called the *path length*),\n",
"“cycles/instruction” is the number of CPU clock cycles each instruction\n",
"requires, and “cycle time” is the actual time it takes for one CPU\n",
"cycle. After thinking about (10.3), we can understand the CISC\n",
"philosophy that tries to reduce CPU time by reducing the number of\n",
"instructions, as well as the RISC philosophy, which tries to reduce the\n",
"CPU time by reducing cycles/instruction (preferably to 1).For RISC to\n",
"achieve an increase in performance requires a greater decrease in cycle\n",
"time and cycles/instruction than is the increase in the number of\n",
"instructions.\n",
"\n",
"In summary, the elements of RISC are the following:\n",
"\n",
"**Single-cycle execution,**\n",
" for most machine-level instructions.\n",
"\n",
"**Small instruction set,**\n",
" of less than 100 instructions.\n",
"\n",
"**Register-based instructions,**\n",
" operating on values in registers, with memory access confined to\n",
"loading from and storing to registers.\n",
"\n",
"**Many registers,**\n",
" usually more than 32.\n",
"\n",
"**Pipelining,**\n",
" concurrent preparation of several instructions that are then\n",
"executed successively.\n",
"\n",
"**High-level compilers,**\n",
" to improve performance.\n",
"\n",
"## 10.5 CPU Design: Multiple-Core Processors\n",
"\n",
"The present time is seeing a rapid increase in the inclusion multicore\n",
"(now up to 128) chips as the computational engine of computers, and we\n",
"expect that number to keep rising. As seen in Figure 10.4, a dual-core\n",
"chip has two CPU’s in one integrated circuit with a shared interconnect\n",
"and a shared level-2 cache. This type of configuration with two or more\n",
"identical processors connected to a single shared main memory is called\n",
"*symmetric multiprocessing*, or SMP.\n",
"\n",
"|Figure 10.4 A|Figure 10.4 B|\n",
"|:- - -:|:- - -:|\n",
"| 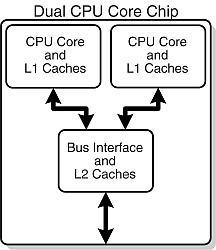| |\n",
"\n",
"\n",
"**Figure 10.4** *Top:* A generic view of the Intel core-2 dual-core processor,\n",
"with CPU-local level-1 caches and a shared, on-die level-2 cache (courtesy of D.\n",
"Schmitz). *Bottom:* THE AMD Athlon 64 X2 3600 dual-core CPU (Wikimedia\n",
"Commons).\n",
"\n",
"Although multicore chips were originally designed for game playing and\n",
"single precision, they are finding use in scientific computing as new\n",
"tools, algorithms, and programming methods are employed. These chips\n",
"attain more integrated speed with less heat and more energy efficiency\n",
"than single-core chips, whose heat generation limits them to clock\n",
"speeds of less than 4 GHz. In contrast to multiple single-core chips,\n",
"multicore chips use fewer transistors per CPU and are thus simpler to\n",
"make and cooler to run.\n",
"\n",
"Parallelism is built into a multicore chip because each core can run a\n",
"different task. However, because the cores usually share the same\n",
"communication channel and level-2 cache, there is the possibility of a\n",
"communication bottleneck if both CPU’s use the bus at the same time.\n",
"Usually the user need not worry about this, but the writers of compilers\n",
"and software must. Modern compilers automatically make use of the\n",
"multiple cores, with MPI even treating each core as a separate\n",
"processor.\n",
"\n",
"## 10.6 CPU Design: Vector Processors\n",
"\n",
"Often the most demanding part of a scientific computation involves\n",
"matrix operations. On a classic (von Neumann) scalar computer, the\n",
"addition of two vectors of physical length 99 to form a third,\n",
"ultimately requires 99 sequential additions (Table 10.2). There is\n",
"actually much behind-the-scenes work here. For each element *i* there is\n",
"the *fetch* of *a*(*i*) from its location in memory, the *fetch* of\n",
"*b*(*i*) from its location in memory, the *addition* of the numerical\n",
"values of these two elements in a CPU register, and the *storage* in\n",
"memory of the sum in *c*(*i*). This fetching uses up time and is\n",
"wasteful in the sense that the computer is being told again and again to\n",
"do the same thing.\n",
"\n",
"When we speak of a computer doing *vector processing*, we mean that\n",
"there are hardware components that perform mathematical operations on\n",
"entire rows or columns of matrices as opposed to individual elements.\n",
"(This hardware can also handle single-subscripted matrices, that is,\n",
"mathematical vectors.) In the vector processing of\n",
"\\[*A*\\]+\\[*B*\\]=\\[*C*\\], the successive fetching of and addition of the\n",
"elements *A* and *B* are grouped together and overlaid, and *Z* ≃ 64−256\n",
"elements (the *section size*) are processed with one command, as seen in\n",
"Table 10.2. Depending on the array size, this method may speed up the\n",
"processing of vectors by a factor of approximately 10. If all *Z*\n",
"elements were truly processed in the same step, then the speedup would\n",
"be ∼64−256.\n",
"\n",
"Vector processing probably had its heyday during the time when computer\n",
"manufacturers produced large mainframe computers designed for the\n",
"scientific and military communities. These computers had proprietary\n",
"hardware and software and were often so expensive that only corporate or\n",
"military laboratories could afford them. While the Unix and then PC\n",
"revolutions have nearly eliminated these large vector machines, some do\n",
"exist, as well as PC’s that use vector processing in their video cards.\n",
"Who is to say what the future holds in store?"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"**Table 10.2** Computation of Matrix \\[*C*\\]=\\[*A*\\]+\\[*B*\\].\n",
"\n",
"| *Step 1* | *Step 2* |⋯ | *Step 99*|\n",
"|- - -|:- - -:|:- - -:|:- - -:|\n",
"|*c*(1)=*a*(1)+*b*(1) | *c*(2)=*a*(2)+*b*(2) |⋯ |*c*(99)=*a*(99)+*b*(99)|\n",
"\n",
"## 10.7 Introduction to Parallel Computing\n",
"\n",
"There is little question that advances in the hardware for parallel\n",
"computing are impressive. Unfortunately, the software that accompanies\n",
"the hardware often seems stuck in the 1960s. In our view, message\n",
"passing has too many details for application scientists to worry about\n",
"and (unfortunately) requires coding at an elementary level reminiscent\n",
"of the early days of computing. However, the increasing occurrence of\n",
"clusters in which the nodes are symmetric multiprocessors has led to the\n",
"development of sophisticated compilers that follow simpler programming\n",
"models; for example, *partitioned global address space* compilers such\n",
"as *CoArray Fortran*, *Unified Parallel C*, and *Titanium*. In these\n",
"approaches the programmer views a global array of data and then\n",
"manipulates these data as if they were contiguous. Of course the data\n",
"really are distributed, but the software takes care of that outside the\n",
"programmer’s view. Although such a program may make use of processors\n",
"less efficiently than would a hand-coded program, it is a lot easier\n",
"than redesigning your program. Whether it is worth *your* time to make a\n",
"program more efficient depends on the problem at hand, the number of\n",
"times the program will be run, and the resources available for the task.\n",
"In any case, if each node of the computer has a number of processors\n",
"with a shared memory and there are a number of nodes, then some type of\n",
"a hybrid programming model will be needed.\n",
"\n",
"**Vector Processing of Matrix \\[*A*\\]+\\[*B*\\]=\\[*C*\\].**\n",
"\n",
"| Step 1 | Step 2 | ⋯ | Step *Z* |\n",
"|- - -|:- - -:|:- - -:|:- - -:|\n",
"|*c*(1)=*a*(1)+*b*(1) ||| |\n",
"| |*c*(2)=*a*(2)+*b*(2)|| |\n",
"| | | ⋯||\n",
"| | | |*c*(*Z*)=*a*(*Z*)+*b*(*Z*)|\n",
"\n",
"## 10.8 Parallel Semantics (Theory)\n",
"\n",
"We saw earlier that many of the tasks undertaken by a high-performance\n",
"computer are run in parallel by making use of internal structures such\n",
"as pipelined and segmented CPU’s, hierarchical memory, and separate I/O\n",
"processors. While these tasks are run “in parallel,” the modern use of\n",
"*parallel computing* or *parallelism* denotes applying multiple\n",
"processors to a single problem \\[Quinn(04)\\]. It is a computing\n",
"environment in which some number of CPU’s are running asynchronously and\n",
"communicating with each other in order to exchange intermediate results\n",
"and coordinate their activities.\n",
"\n",
"For an instance, consider the matrix multiplication:\n",
"\n",
"$$\\tag*{10.4} [B] = [A][B].$$\n",
"\n",
"Mathematically, this equation makes no sense unless \\[*A*\\] equals the identity\n",
"matrix \\[*I*\\]. However, it does make sense as an algorithm that produces new\n",
"value of *B* on the LHS in terms of old values of *B* on the RHS:\n",
"\n",
"$$\\begin{align}\n",
"\\tag*{10.5}\n",
"[B^{\\mbox{new}}] & = [A][B^{\\mbox{old}}]\\\\\n",
"\\Rightarrow \\ B^{\\mbox{new}}_{i,j} & = \\sum_{k=1}^N\n",
"A_{i,k}B^{\\mbox{old}}_{k,j}.\\tag*{10.6}\\end{align}$$\n",
"\n",
" Because the computation of *B**i*, *j**new*\n",
"for specific values of *i* and *j* is independent of the computation of all the\n",
"other values of *B**i*, *j**new*, each\n",
"*B**i*, *j**new* can be computed in parallel, or each\n",
"row or column of \\[*B**new*\\] can be computed in parallel. If *B*\n",
"were not a matrix, then we could just calculate *B* = *AB* with no further ado.\n",
"However, if we try to perform the calculation using just matrix elements of\n",
"\\[*B*\\] by replacing the old values with the new values as they are computed,\n",
"then we must somehow establish that the *B**k*, *j* on the RHS\n",
"of (10.6) are the values of \\[*B*\\] that existed *before* the matrix\n",
"multiplication.\n",
"\n",
"This is an example of *data dependency*, in which the data elements used\n",
"in the computation depend on the order in which they are used. A way to\n",
"account for this dependency is to use a temporary matrix for\n",
"\\[*B**new*\\], and then to assign \\[*B*\\] to the temporary\n",
"matrix after all multiplications are complete:\n",
"\n",
"$$\\begin{align}\n",
"\\tag*{10.7}\n",
"[\\mbox{Temp}] & = [A][B] \\mbox{} \\\\ [B] & =\n",
"[\\mbox{Temp}].\\tag*{10.8}\\end{align}$$\n",
"\n",
"In contrast, the matrix multiplication \\[*C*\\]=\\[*A*\\]\\[*B*\\] is a *data\n",
"parallel* operation in which the data can be used in any order.So\n",
"already we see the importance of communication, synchronization, and\n",
"understanding of the mathematics behind an algorithm for parallel\n",
"computation.\n",
"\n",
"The processors in a parallel computer are placed at the *nodes* of a\n",
"communication network. Each node may contain one CPU or a small number\n",
"of CPU’s, and the communication network may be internal to or external\n",
"to the computer. One way of categorizing parallel computers is by the\n",
"approach they utilize in handling instructions and data. From this\n",
"viewpoint there are three types of machines:\n",
"\n",
"**Single-instruction, single-data (SISD):**\n",
"These are the classic (von Neumann) serial computers executing a single\n",
"instruction on a single data stream before the next instruction and next\n",
"data stream are encountered.\n",
"\n",
"**Single-instruction, multiple-data (SIMD):**\n",
"Here instructions are processed from a single stream, but the\n",
"instructions act concurrently on multiple data elements. Generally the\n",
"nodes are simple and relatively slow but are large in number.\n",
"\n",
"**Multiple instructions, multiple data (MIMD):**\n",
"In this category each processor runs independently of the others with\n",
"independent instructions and data. These are the types of machines that\n",
"utilize *message-passing* packages, such as MPI, to communicate\n",
"among processors. PCs linked via a network, or more integrated machines\n",
"with thousands of processors on internal boards, such as the Blue Gene\n",
"computer described in § 10.15. These computers, which do not have a\n",
"shared memory space, are also called *multicomputers*. Although these\n",
"types of computers are some of the most difficult to program, their low\n",
"cost and effectiveness for certain classes of problems have led to their\n",
"being the dominant type of parallel computer at present.\n",
"\n",
"The running of independent programs on a parallel computer is similar to\n",
"the multitasking feature used by Unix and PC’s. In multitasking\n",
"(Figure 10.5 A) several independent programs reside in the computer’s\n",
"memory simultaneously and share the processing time in a round robin or\n",
"priority order. On a SISD computer, only one program runs at a single\n",
"time, but if other programs are in memory, then it does not take long to\n",
"switch to them. In multiprocessing (Figure 10.5 B) these jobs may all\n",
"run at the same time, either in different parts of memory or in the\n",
"memory of different computers. Clearly, multiprocessing becomes\n",
"complicated if separate processors are operating on different parts of\n",
"the *same* program because then synchronization and load balance\n",
"(keeping all the processors equally busy) are concerns.\n",
"\n",
"In addition to instructions and data streams, another way of\n",
"categorizing parallel computation is by *granularity*. A *grain* is\n",
"defined as a measure of the computational work to be performed, more\n",
"specifically, the ratio of computation work to communication work.\n",
"\n",
"**Coarse-grain parallel:**\n",
"Separate programs running on separate computer systems with the systems\n",
"coupled via a conventional communication network. An illustration is six\n",
"Linux PC’s sharing the same files across a network but with a different\n",
"central memory system for each PC. Each computer can be operating on a\n",
"different, independent part of one problem at the same time.\n",
"\n",
"**Medium-grain parallel:**\n",
"Several processors executing (possibly different) programs\n",
"simultaneously while accessing a common memory. The processors are\n",
"usually placed on a common *bus* (communication channel) and communicate\n",
"with each other through the memory system. Medium-grain programs have\n",
"different, independent, *parallel subroutines* running on\n",
"different processors. Because the compilers are seldom smart enough to\n",
"figure out which parts of the program to run where, the user must\n",
"include the multitasking routines in the program.\\[*Note:* Some experts\n",
"define our medium grain as coarse grain yet this distinction changes\n",
"with time.\\]\n",
"\n",
"**Fine-grain parallel:**\n",
"As the granularity decreases and the number of nodes increases, there is\n",
"an increased requirement for fast communication among the nodes. For\n",
"this reason fine-grain systems tend to be custom-designed machines. The\n",
"communication may be via a central bus or via shared memory for a small\n",
"number of nodes, or through some form of high-speed network for\n",
"massively parallel machines. In the latter case, the user typically\n",
"divides the work via certain coding constructs, and the compiler just\n",
"compiles the program. The program then runs concurrently on a\n",
"user-specified number of nodes. For example, different `for` loops of a\n",
"program may be run on different nodes.\n",
"\n",
" **Figure 10.5** *Top:* Multitasking of four\n",
"programs in memory at one time. On a SISD computer the programs are\n",
"executed in round robin order. *Bottom:* Four programs in the four\n",
"separate memories of a MIMD computer.\n",
"\n",
"10.9 Distributed Memory Programming\n",
"\n",
"An approach to concurrent processing that, because it is built from\n",
"commodity PC’s, has gained dominant acceptance for coarse- and\n",
"medium-grain systems is *distributed memory*. In it, each processor has\n",
"its own memory and the processors exchange data among themselves through\n",
"a high-speed switch and network. The data exchanged or *passed* among\n",
"processors have encoded *to* and *from* addresses and are called\n",
"*messages*. The *clusters* of PC’s or workstations that constitute a\n",
"*Beowulf*\\[*Note:* Presumably there is an analogy between the heroic\n",
"exploits of the son of Ecgtheow and the nephew of Hygelac in the 1000\n",
"C.E. poem *Beowulf* and the adventures of us common folk assembling\n",
"parallel computers from common elements that have surpassed the\n",
"performance of major corporations and their proprietary,\n",
"multi-million-dollar supercomputers.\\] are examples of distributed\n",
"memory computers (Figure 10.6). The unifying characteristic of a cluster\n",
"is the integration of highly replicated compute and communication\n",
"components into a single system, with each node still able to operate\n",
"independently. In a Beowulf cluster, the components are commodity ones\n",
"designed for a general market, as are the communication network and its\n",
"high-speed switch (special interconnects are used by major commercial\n",
"manufacturers, but they do not come cheaply). *Note*: A group of\n",
"computers connected by a network may also be called a cluster but unless\n",
"they are designed for parallel processing, with the same type of\n",
"processor used repeatedly and with only a limited number of processors\n",
"(the *front end*) onto which users may log in, they are not usually\n",
"called a Beowulf.\n",
"\n",
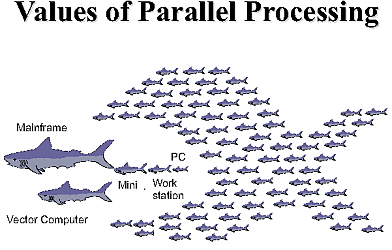
"|Figure 10.6 A| Figure 10.6 B|\n",
"|:- - -:|:- - -:|\n",
"|| |\n",
"\n",
"**Figure 10.6** Two views of parallel computing (courtesy of Yuefan Deng).\n",
"\n",
"The literature contains frequent arguments concerning the differences\n",
"among clusters, commodity clusters, Beowulfs, constellations, massively\n",
"parallel systems, and so forth \\[Dongarra et al.(05)\\]. Although we\n",
"recognize that there are major differences between the clusters on the\n",
"top 500 list of computers and the ones that a university researcher may\n",
"set up in his or her lab, we will not distinguish these fine points in\n",
"the introductory materials we present here.\n",
"\n",
"For a message-passing program to be successful, the data must be divided\n",
"among nodes so that, at least for a while, each node has all the data it\n",
"needs to run an independent subtask. When a program begins execution,\n",
"data are sent to all the nodes. When all the nodes have completed their\n",
"subtasks, they exchange data again in order for each node to have a\n",
"complete new set of data to perform the next subtask. This repeated\n",
"cycle of data exchange followed by processing continues until the full\n",
"task is completed. Message-passing MIMD programs are also\n",
"*single-program, multiple-data* programs, which means that the\n",
"programmer writes a single program that is executed on all the nodes.\n",
"Often a separate host program, which starts the programs on the nodes,\n",
"reads the input files and organizes the output.\n",
"\n",
"## 10.10 Parallel Performance\n",
"\n",
"Imagine a cafeteria line in which all the servers appear to be working\n",
"hard and fast yet the ketchup dispenser has some relish partially\n",
"blocking its output and so everyone in line must wait for the ketchup\n",
"lovers up front to ruin their food before moving on. This is an example\n",
"of the slowest step in a complex process determining the overall rate.\n",
"An analogous situation holds for parallel processing, where the ketchup\n",
"dispenser may be a relatively small part of the program that can be\n",
"executed only as a series of serial steps. Because the computation\n",
"cannot advance until these serial steps are completed, this small part\n",
"of the program may end up being the bottleneck of the program.\n",
"\n",
"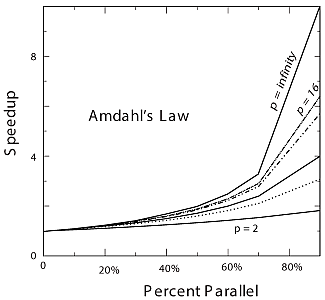\n",
"\n",
"**Figure 10.7** The theoretical maximum speedup of a program as a function\n",
"of the fraction of the program that potentially may be run in parallel. The\n",
"different curves correspond to different numbers of processors.\n",
"\n",
"As we soon will demonstrate, the speedup of a program will not be\n",
"significant unless you can get ∼90% of it to run in parallel, and even\n",
"then most of the speedup will probably be obtained with only a small\n",
"number of processors. This means that you need to have a computationally\n",
"intense problem to make parallelization worthwhile, and that is one of\n",
"the reasons why some proponents of parallel computers with thousands of\n",
"processors suggest that you not apply the new machines to old problems\n",
"but rather look for new problems that are both big enough and\n",
"well-suited for massively parallel processing to make the effort\n",
"worthwhile.\n",
"\n",
"The equation describing the effect on speedup of the balance between\n",
"serial and parallel parts of a program is known as Amdahl’s law\n",
"\\[Amdahl(67), Quinn(04)\\]. Let\n",
"\n",
"$$p = \\mbox{number of CPU's,}\\quad T_{1} = \\mbox{time to run on 1 CPU},\n",
"\\quad T_{p} = \\mbox{time to run on $p$ CPU's}.$$\n",
"\n",
"The maximum speedup *S**p* attainable with parallel\n",
"processing is thus\n",
"\n",
"$$\\tag*{10.10}\n",
" S_{p} = \\frac{T_{1}}{T_{p}} \\rightarrow p.$$\n",
"\n",
"In practise this limit is never met for a number of reasons: some of the\n",
"program is serial, data and memory conflicts occur, communication and\n",
"synchronization of the processors take time, and it is rare to attain a\n",
"perfect load balance among all the processors.For the moment we ignore\n",
"these complications and concentrate on how the *serial* part of the code\n",
"affects the speedup. Let *f* be the fraction of the program that\n",
"potentially may run on multiple processors. parallel must be run via\n",
"serial processing and thus takes time:\n",
"\n",
"$$\\tag*{10.11} T_{s} = (1-f) T_{1} \\quad \\mbox{(serial time)}.$$\n",
"\n",
"The time *T**p* spent on the *p* parallel processors is related to\n",
"*T**s* by $$\\tag*{10.12} T_{p} = f \\; \\frac{T_{1}}{p}.$$\n",
"\n",
"That being so, the maximum speedup as a function of *f* and the number\n",
"of processors is\n",
"\n",
"$$\\tag*{10.13}\n",
" S_{p} = \\frac{T_{1}}{T_{s} + T_{p}} =\n",
"\\frac{1}{1-f+f/p} \\quad \\mbox{(Amdahl's law)}.$$\n",
"\n",
"Some theoretical speedups are shown in Figure 10.7 for different numbers\n",
"of processors *p*. Clearly the speedup will not be significant enough to\n",
"be worth the trouble unless most of the code is run in parallel (this is\n",
"where the 90% of the in-parallel figure comes from). Even an infinite\n",
"number of processors cannot increase the speed of running the serial\n",
"parts of the code, and so it runs at one processor speed. In practice\n",
"this means many problems are limited to a small number of processors,\n",
"and that only 10%-20% of the computer’s peak performance is often all\n",
"that is obtained for realistic applications.\n",
"\n",
"### 10.10.1 Communication Overhead\n",
"\n",
"As discouraging as Amdahl’s law may seem, it actually *overestimates*\n",
"speedup because it ignores the *overhead* for parallel computation. Here\n",
"we look at communication overhead. Assume a completely parallel code so\n",
"that its speedup is\n",
"\n",
"$$\\tag*{10.14}\n",
" S_{p} = \\frac{T_{1}}{T_{p}} = \\frac{T_{1}}{T_{1}/p}= p .$$\n",
"\n",
"The denominator is based on the assumption that it takes no time for the\n",
"processors to communicate. However, in reality it takes a finite time,\n",
"called *latency*, to get data out of memory and into the cache or onto\n",
"the communication network. In addition, a communication channel also has\n",
"a finite *bandwidth*, that is, a maximum rate at which data can be\n",
"transferred, and this too will increase the *communication time* as\n",
"large amounts of data are transferred. When we include communication\n",
"time *T**c*, the speedup decreases to\n",
"\n",
"$$\\tag*{10.15} S_{p} \\simeq \\frac{T_{1}}{T_{1}/p + T_{c}} \\lt; p\n",
"\\quad\\mbox{(with communication time)}.$$\n",
"\n",
"For the speedup to be unaffected by communication time, we need to have\n",
"\n",
"$$\\tag*{10.16}\n",
"\\frac{T_{1}}{p} \\gg T_{c}\\enskip \\Rightarrow \\enskip p \\ll\n",
"\\frac{T_{1}}{T_{c}}.$$\n",
"\n",
"This means that as you keep increasing the number of processors *p*, at\n",
"some point the time spent on computation *T*1/*p* must equal\n",
"the time *T**c* needed for communication, and adding more\n",
"processors leads to greater execution time as the processors wait around\n",
"more to communicate. This is another limit, then, on the maximum number\n",
"of processors that may be used on any one problem, as well as on the\n",
"effectiveness of increasing processor speed without a commensurate\n",
"increase in communication speed.\n",
"\n",
"The continual and dramatic increase in the number of processors being\n",
"used in computations is leading to a changing view as to how to judge\n",
"the speed of an algorithm. Specifically, the slowest step in a process\n",
"is usually the rate-determining step, yet with the increasing\n",
"availability of CPU power the slowest step is more often the access to\n",
"or communication among processors. Such being the case, while the number\n",
"of computational steps is still important for determining an algorithm’s\n",
"speed, the number and amount of memory access and interprocessor\n",
"communication must also be mixed into the formula. This is currently an\n",
"active area of research in algorithm development.\n",
"\n",
"## 10.11 Parallelization Strategies\n",
"\n",
"A typical organization of a program containing both serial and parallel\n",
"tasks is given in Table 10.4. The user organizes the work into units\n",
"called *tasks*, with each task assigning work (*threads*) to a\n",
"processor. The main task controls the overall execution as well as the\n",
"subtasks that run independent parts of the program (called *parallel\n",
"subroutines*, *slaves*, *guests*, or *subtasks*).These parallel\n",
"subroutines can be distinctive subprograms, multiple copies of the same\n",
"subprogram, or even Python `for` loops.\n",
"\n",
"**Table 10.4** A typical organization of a program containing both\n",
"serial and parallel tasks.\n",
"\n",
"||| |\n",
"|:- - -: |:- - -: |:- - -:|\n",
"| |Main task program||\n",
"| |↓||\n",
"| |Main routine | |\n",
"| |↓||\n",
"| |Serial subroutine a||\n",
"||↓||\n",
"|↓ | ↓ | ↓ |\n",
"|Parallel sub 1| Parallel sub 2 | Parallel sub 3|\n",
"|↓ | ↓ | ↓|\n",
"| |↓||\n",
"| |Summation task||\n",
"It is the programmer’s responsibility to establish that the breakup of a\n",
"code into parallel subroutines is mathematically and scientifically\n",
"valid and is an equivalent formulation of the original program. As a\n",
"case in point, if the most intensive part of a program is the evaluation\n",
"of a large Hamiltonian matrix, you may want to evaluate each row on a\n",
"different processor. Consequently, the key to parallel programming is to\n",
"identify the parts of the program that may benefit from parallel\n",
"execution. To do that the programmer should understand the program’s\n",
"data structures (discussed soon), know in what order the steps in the\n",
"computation must be performed, and know how to coordinate the results\n",
"generated by different processors.\n",
"\n",
"The programmer helps speed up the execution by keeping many processors\n",
"simultaneously busy and by avoiding storage conflicts among different\n",
"parallel subprograms. You do this *load balancing* by dividing your\n",
"program into subtasks of approximately equal numerical intensity that\n",
"will run simultaneously on different processors. The rule of thumb is to\n",
"make the task with the largest granularity (workload) dominant by\n",
"forcing it to execute first and to keep all the processors busy by\n",
"having the number of tasks an integer multiple of the number of\n",
"processors. This is not always possible.\n",
"\n",
"The individual parallel threads can have *shared* or *local* data. The\n",
"shared data may be used by all the machines, while the local data are\n",
"private to only one thread. To avoid storage conflicts, design your\n",
"program so that parallel subtasks use data that are independent of the\n",
"data in the main task and in other parallel tasks. This means that these\n",
"data should not be modified *or even examined* by different tasks\n",
"simultaneously. In organizing these multiple tasks, reduce communication\n",
"*overhead costs* by limiting communication and synchronization. These\n",
"costs tend to be high for fine-grain programming where much coordination\n",
"is necessary. However, *do not* eliminate communications that are\n",
"necessary to ensure the scientific or mathematical validity of the\n",
"results; bad science can do harm!\n",
"\n",
"## 10.12 Practical Aspects of MIMD Message Passing\n",
"\n",
"It makes sense to run only the most numerically intensive codes on\n",
"parallel machines. Frequently these are very large programs assembled\n",
"over a number of years or decades by a number of people. It should come\n",
"as no surprise, then, that the programming languages for parallel\n",
"machines are primarily Fortran, which now has explicit structures for\n",
"the compiler to parallelize, and C. (In the past we have not obtained\n",
"good speedup with Java and MPI, yet we are told that *FastMPJ* and *MPJ\n",
"Express* have fixed the problems.)\n",
"\n",
"Effective parallel programming becomes more challenging as the number of\n",
"processors increases. Computer scientists suggest that it is best *not*\n",
"to attempt to modify a serial code but instead to rewrite one from\n",
"scratch using algorithms and subroutine libraries best suited to\n",
"parallel architecture. However, this may involve months or years of\n",
"work, and surveys find that ∼70% of computational scientists revise\n",
"existing codes instead \\[Pancake(96)\\].\n",
"\n",
"Most parallel computations at present are performed on\n",
"multiple-instruction, multiple-data computers via message passing using\n",
"MPI. Next we outline some practical concerns based on user experience\n",
"\\[Dongarra et al.(05), Pancake(96)\\].\n",
"\n",
"**Parallelism carries a price tag:**\n",
" There is a steep learning curve requiring intensive effort. Failures\n",
"may occur for a variety of reasons, especially because parallel\n",
"environments tend to change often and get “locked up” by a\n",
"programming error. In addition, with multiple computers and multiple\n",
"operating systems involved, the familiar techniques for debugging may\n",
"not be effective.\n",
"\n",
"Preconditions for parallelism:\n",
" If your program is run thousands of times between changes, with\n",
"execution time in days, and you must significantly increase the\n",
"resolution of the output or study more complex systems, then parallelism\n",
"is worth considering. Otherwise, and to the extent of the difference,\n",
"parallelizing a code may not be worth the time investment.\n",
"\n",
"The problem affects parallelism:\n",
" You must analyze your problem in terms of how and when data are used,\n",
"how much computation is required for each use, and the type of\n",
"problem architecture.\n",
"\n",
"Perfectly parallel: \n",
"The same application is run simultaneously on different data sets, with\n",
"the calculation for each data set independent (e.g., running multiple\n",
"versions of a Monte Carlo simulation, each with different seeds, or\n",
"analyzing data from independent detectors). In this case it would be\n",
"straightforward to parallelize with a respectable performance to\n",
"be expected.\n",
"\n",
"Fully synchronous: \n",
"The same operation applied in parallel to multiple parts of the same\n",
"data set, with some waiting necessary (e.g., determining positions and\n",
"velocities of particles simultaneously in a molecular\n",
"dynamics simulation). Significant effort is required, and unless you\n",
"balance the computational intensity, the speedup may not be worth\n",
"the effort.\n",
"\n",
"Loosely synchronous: \n",
"Different processors do small pieces of the computation but with\n",
"intermittent data sharing (e.g., diffusion of groundwater from one\n",
"location to another). In this case it would be difficult to parallelize\n",
"and probably not worth the effort.\n",
"\n",
"Pipeline parallel: \n",
"Data from earlier steps processed by later steps, with some overlapping\n",
"of processing possible (e.g., processing data into images and then\n",
"into animations). Much work may be involved, and unless you balance the\n",
"computational intensity, the speedup may not be worth the effort.\n",
"\n",
"### 10.11.1 High-Level View of Message Passing\n",
"\n",
"Although it is true that parallel computing programs may become very\n",
"complicated, the basic ideas are quite simple. All you need is a regular\n",
"programming language like Python, C or Fortran, plus four communication\n",
"statements:\\[*Note:* Personal communication, Yuefan Deng.\\]\n",
"\n",
"- **`send`:** One processor sends a message to the network.\n",
"\n",
"- **`receive:`** One processor receives a message from the network.\n",
"\n",
"- **`myid`:** An integer that uniquely identifies each processor.\n",
"\n",
"- **`numnodes`:** An integer giving the total number of nodes in\n",
" the system.\n",
"\n",
"Once you have made the decision to run your program on a computer\n",
"cluster, you will have to learn the specifics of a message-passing\n",
"system such as MPI. Here we give a broader view. When you write a\n",
"message-passing program, you intersperse calls to the message-passing\n",
"library with your regular Python, Fortran or C program. The basic steps\n",
"are\n",
"\n",
"1. Submit your job from the command line or a job control system.\n",
"\n",
"2. Have your job start additional processes.\n",
"\n",
"3. Have these processes exchange data and coordinate their activities.\n",
"\n",
"4. Collect these data and have the processes stop themselves.\n",
"\n",
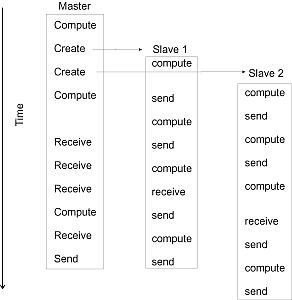
"We show this graphically in Figure 10.8 where at the top we see a\n",
"*master* process create two *slave* processes and then assign work for\n",
"them to do (arrows). The processes then communicate with each other via\n",
"message passing, output their data to files, and finally terminate.\n",
"\n",
"\n",
"\n",
" **Figure 10.8** A master process and two slave\n",
"processes passing messages. Notice how in this not-well-designed program\n",
"there are more sends than receives, and consequently the results may depend\n",
"upon the order of execution, or the program may even lock up.\n",
"\n",
"**What can go wrong:** Figure 10.8 also illustrates some of the\n",
"difficulties:\n",
"\n",
"- The programmer is responsible for getting the processes to cooperate\n",
" and for dividing the work correctly.\n",
"\n",
"- The programmer is responsible for ensuring that the processes have\n",
" the correct data to process and that the data are\n",
" distributed equitably.\n",
"\n",
"- The commands are at a lower level than those of a compiled language,\n",
" and this introduces more details for you to worry about.\n",
"\n",
"- Because multiple computers and multiple operating systems are\n",
" involved, the user may not receive or understand the error\n",
" messages produced.\n",
"\n",
"- It is possible for messages to be sent or received not in the\n",
" planned order.\n",
"\n",
"- A *race condition* may occur in which the program results depend\n",
" upon the specific ordering of messages. There is no guarantee that\n",
" slave 1 will get its work performed before slave 2, even though\n",
" slave 1 may have started working earlier (Figure 10.8).\n",
"\n",
"- Note in Figure 10.8 how different processors must wait for signals\n",
" from other processors; this is clearly a waste of time and has\n",
" potential for deadlock.\n",
"\n",
"- Processes may *deadlock*, that is, wait for a message that\n",
" never arrives.\n",
"\n",
"### 10.11.2 Message Passing Example & Exercise\n",
"\n",
"Start with a simple serial program you have already written that is a\n",
"good candidate for parallelization. Specifically, one that steps through\n",
"parameter space in order to generate its results is a good candidate\n",
"because you can have parallel tasks working on different regions of\n",
"parameter space. Alternatively, a Monte-Carlo calculation that repeats\n",
"the same step many times is also a good candidate because you can run\n",
"copies of the program on different processors, and then add up the\n",
"results at the end. For example, here is a serial calculation of *π* by\n",
"Monte-Carlo integration in the C language:\n",
"\n",
" // pi.c: *Monte-Carlo integration to determine pi\n",
"\n",
" #include \n",
" #include \n",
"\n",
" // if you don't have drand48 uncomment the following two lines\n",
" // #define drand48 1.0/RAND_MAX*rand\n",
" // #define srand48 srand\n",
"\n",
" #define max 1000 // number of stones to be thrown\n",
" #define seed 68111 // seed for number generator\n",
"\n",
" main() {\n",
"\n",
" int i, pi = 0;\n",
" double x, y, area;\n",
" FILE *output; // save data in pond.dat\n",
" output = fopen(\"pond.dat\",\"w\");\n",
" srand48(seed); // seed the number generator\n",
" for (i = 1; i<= max; i++) {\n",
" x = drand48()*2-1; // creates floats between\n",
" y = drand48()*2-1; // 1 and -1\n",
" if ((x*x + y*y)<1) pi++; // stone hit the pond\n",
" area = 4*(double)pi/i; // calculate area\n",
" fprintf(output, \"%i\\t%f\\n\", i, area);\n",
" }\n",
" printf(\"data stored in pond.dat\\n\");\n",
" fclose(output);\n",
" }\n",
"\n",
"Modify your serial program so that different processors are used and\n",
"perform independently, and then have all their results combined. For\n",
"example, here is a parallel version of pi.c that uses the\n",
"Message Passing Interface (MPI). You may want to concentrate on the\n",
"arithmetic commands and not the MPI ones at this point.\n",
"\n",
"**MPI.c:** Parallel Calculation of *π* by Monte-Carlo integration using\n",
"MPI.\n",
"\n",
" /* MPI.c uses a monte carlo method to compute PI by Stone Throwing */\n",
" /* Based on http://www.dartmouth.edu/~rc/classes/soft_dev/mpi.html */\n",
" /* Note: if the sprng library is not available, you may use rnd */\n",
" #include \n",
" #include \n",
" #include \n",
" #include \n",
" #include \n",
" #include \n",
" #include \n",
" #define USE_MPI\n",
" #define SEED 35791246\n",
" main(int argc, char *argv[])\n",
" {\n",
" int niter=0;\n",
" double x,y;\n",
" int i,j,count=0,mycount; /* # of points in the 1st quadrant of unit circle */\n",
" double z;\n",
" double pi;\n",
" int myid,numprocs,proc;\n",
" MPI_Status status;\n",
" int master =0;\n",
" int tag = 123;\n",
" int *stream_id; /* stream id generated by SPRNGS */\n",
" MPI_Init(&argc,&argv);\n",
" MPI_Comm_size(MPI_COMM_WORLD,&numprocs);\n",
" MPI_Comm_rank(MPI_COMM_WORLD,&myid);\n",
"\n",
" if (argc <=1) {\n",
" fprintf(stderr,\"Usage: monte_pi_mpi number_of_iterations\\n\");\n",
" MPI_Finalize();\n",
" exit(-1);\n",
" }\n",
" sscanf(argv[1],\"%d\",&niter); /* 1st argument is the number of iterations*/\n",
"\n",
" /* initialize random numbers */\n",
" stream_id = init_sprng(myid,numprocs,SEED,SPRNG_DEFAULT);\n",
" mycount=0;\n",
" for ( i=0; i\n",
"\n",
"A common discussion at HPC and Supercomputing conferences of the past\n",
"heard application scientists get up, after hearing about the latest\n",
"machine with what seemed like an incredible number of processors, and\n",
"ask “But how can I use such a machine on my problem, which takes hours\n",
"to run, but is not trivially parallel like your example?”. The response\n",
"from the computer scientist was often something like “You just need to\n",
"think up some new problems that are more appropriate to the machines\n",
"being built. Why use a supercomputer for a problem you can solve on a\n",
"modern laptop?” It seems that these anecdotal exchanges have now been\n",
"incorporated into the fabric of parallel computing under the title of\n",
"*scalability*. In the most general sense, *scalability is defined as the\n",
"ability to handle more work as the size of the computer or application\n",
"grows*.\n",
"\n",
"\n",
"\n",
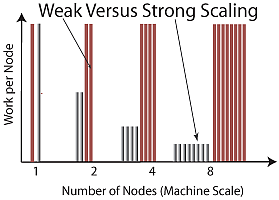
"**Figure 10.10** A graphical representation of weak versus strong scaling.\n",
"Weak scaling keeps each node doing the same amount of work as the problem is\n",
"made bigger. Strong scaling has each node doing less work (running for less\n",
"time) as the number of nodes is made bigger.\n",
"\n",
"As we have already indicated, the primary challenge of parallel\n",
"computing is deciding how best to break up a problem into individual\n",
"pieces that can each be computed separately. In an ideal world a problem\n",
"would *scale* in a linear fashion, that is, the program would speed up\n",
"by a factor of *N* when it runs on a machine having *N* nodes. (Of\n",
"course, as *N* → ∞ the proportionality cannot hold because communication\n",
"time must at some point dominate). In present day terminology, this type\n",
"of scaling is called **strong scaling**, and refers to a situation in\n",
"which the *problem size remains fixed* while the number of number of\n",
"nodes (the *machine scale*) increases. Clearly then, the goal when\n",
"solving a problem that scales strongly is to decrease the amount of time\n",
"it takes to solve the problem by using a more powerful computer. These\n",
"are typically CPU-bound problems and are the hardest ones to yield\n",
"something close to a linear speedup.\n",
"\n",
"In contrast to strong scaling in which the problem size remains fixed,\n",
"in **weak scaling** we have applications of the type our CS colleagues\n",
"referred to above; namely, ones in which we make the problem bigger and\n",
"bigger as the number of processors increases. So here, we would have\n",
"linear or perfect scaling if we could increase the size of the problem\n",
"solved in proportion to the number *N* of nodes.\n",
"\n",
"To illustrate the difference between strong and weak scaling, consider\n",
"Figure 10.10 (based on a lecture by Thomas Sterling). We see that for an\n",
"application that scales perfectly strongly, the work carried out on each\n",
"node decreases as the scale of the machine increases, which of course\n",
"means that the time it takes to complete the problem decreases linearly.\n",
"In contrast, we see that for an application that scales perfectly\n",
"weakly, the work carried out by each node remains the same as the scale\n",
"of the machine increases, which means that we are solving progressively\n",
"larger problems in the same time as it takes to solve smaller ones on a\n",
"smaller machine.\n",
"\n",
"The concepts of weak and strong scaling are ideals that tend not to be\n",
"achieved in practice, with real world applications being a mix of the\n",
"two. Furthermore, it is the combination of application and computer\n",
"architecture that determines the type of scaling that occurs. For\n",
"example, shared memory systems and distributed-memory, message passing\n",
"systems scale differently. Furthermore, a *data parallel* application\n",
"(one in which each node can work on its own separate data set) will by\n",
"its very nature scale weakly.\n",
"\n",
"Before we go on and set you working on some examples of scaling, we\n",
"should introduce a note of caution. Realistic applications tend to have\n",
"various levels of complexity and so it may not be obvious just how to\n",
"measure the increase in “size” of a problem. As an instance, it is known\n",
"that the solution of a set of *N* linear equations via Gaussian\n",
"elimination requires (*N*3) floating-point operations\n",
"(flops). This means that doubling the number of equations does not make\n",
"the “problem” twice as large, but rather eight times as large! Likewise,\n",
"if we are solving partial differential equations on a three-dimensional\n",
"spatial grid and a 1-D time grid, then the problem size would scale like\n",
"*N*4. In this case doubling the problem size would mean\n",
"increasing *N* by only 21/4 ≃ 1.19.\n",
"\n",
"### 10.13.1 Scalability Exercises\n",
"\n",
"We have given above, and included in the Codes directory, a serial code\n",
"pi.c that computes *π*/4 by Monte-Carlo integration of a\n",
"quarter of a unit circle. We have also given the code\n",
"MPIpi.c that computes *π* by the same algorithm using MPI\n",
"to compute the algorithm in parallel. Your exercise is to see how well\n",
"this application scales. You can modify the codes we have given, or you\n",
"can write your own.\n",
"\n",
"1. Determine the CPU time required to calculate *π* with the serial\n",
" calculation using 1000 iterations (stone throws). Make sure that\n",
" this is the actual run time and does not include any system time.\n",
" (You can get this type of information, depending upon the operating\n",
" system, by inserting timer calls in your program.)\n",
"\n",
"2. Get the MPI code running for the same number (1000) of iterations.\n",
"\n",
"3. First we do some running that constitutes a **strong scaling test**.\n",
" This means keeping the problem size constant, or in other words,\n",
" keeping *N**iter* = 1000. Start by running the MPI\n",
" code with only one processor doing the numerical computation. A\n",
" comparison of this to the serial calculation gives you some idea of\n",
" the overhead associated with MPI.\n",
"\n",
"4. Again keeping *N**iter* = 1000, run the MPI code\n",
" for 2, 4, 8 and 16 computing nodes. In any case, make sure to go up\n",
" to enough nodes so that the system no longer scales. Record the run\n",
" time for each number of nodes.\n",
"\n",
"5. Make a plot of run time versus number of nodes from the data you\n",
" have collected.\n",
"\n",
"6. Strong scalability here would yield a straight line graph. Comment\n",
" on your results.\n",
"\n",
"7. Now do some running that constitutes a **weak scaling test**. This\n",
" means increasing the problem size simultaneously with the number of\n",
" nodes being used. In the present case, increasing the number of\n",
" iterations, *N**iter*.\n",
"\n",
"8. Run the MPI code for 2, 4, 8 and 16 computing nodes, with\n",
" proportionally larger values for *N**iter* in each\n",
" case (2000, 4000, 8000, 16,000 *etc.*). In any case, make sure to go\n",
" up to enough nodes so that the system no longer scales.\n",
"\n",
"9. Record the run time for each number of nodes and make a plot of the\n",
" run time versus number of computing nodes.\n",
"\n",
"10. Weak scaling would imply that the runtime remains constant as the\n",
" problem size and the number of compute nodes increase in proportion.\n",
" Comment on your results.\n",
"\n",
"11. Is this problem more appropriate for weak or strong scaling?\n",
"\n",
"## 10.14 Data Parallelism and Domain Decomposition \n",
"\n",
"As you have probably realized by this point, there are two basic, but\n",
"quite different, approaches to creating a program that runs in parallel.\n",
"In **task parallelism** you decompose your program by tasks, with\n",
"differing tasks assigned to different processors, and with great care\n",
"taken to maintain *load balance*, that is, to keep all processors\n",
"equally busy. Clearly you must understand the internal workings of your\n",
"program in order to do this, and you must also have made an accurate\n",
"*profile* of your program so that you know how much time is being spent\n",
"in various parts.\n",
"\n",
"In **data parallelism** you decompose your program based on the data\n",
"being created or acted upon, with differing data spaces (**domains**)\n",
"assigned to different processors. In data parallelism there often must\n",
"be data shared at the boundaries of the data spaces, and therefore\n",
"synchronization among the data spaces. Data parallelism is the most\n",
"common approach and is well suited to message-passing machines in which\n",
"each node has its own private data space, although this may lead to a\n",
"large amount of data transfer at times.\n",
"\n",
"When planning how to decompose global data into subspaces suitable for\n",
"parallel processing, it is important to divide the data into contiguous\n",
"blocks in order to minimize the time spent on moving data through the\n",
"different stages of memory (page faults). Some compilers and operating\n",
"systems help you in this regard by exploiting **spatial locality**, that\n",
"is, by assuming that if you are using a data element at one location in\n",
"data space, then it is likely that you may use some nearby ones as well,\n",
"and so they too are made readily available. Some compilers and operating\n",
"systems also exploit **temporal locality**, that is, by assuming that if\n",
"you are using a data element at one time, then there is an increased\n",
"probability that you may use it again in the near future, and so it too\n",
"is kept handy. You can help optimize your programs by taking advantage\n",
"of these localities while programming.\n",
"\n",
"\n",
"\n",
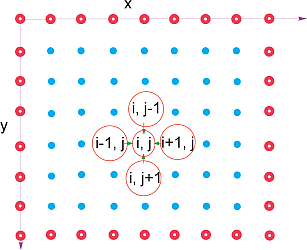
" **Figure 10.11** A representation of the lattice in\n",
"a 2-D rectangular space upon which Laplace’s equation is solved using a finite\n",
"difference approach. The lattice sites with white centers correspond to the\n",
"boundary of the physical system, upon which boundary conditions must be\n",
"imposed for a unique solution. The large circles in the middle of the lattice\n",
"represent the algorithm used to solve Laplace’s equation in which the potential\n",
"at the point (*x*, *y*)=(*i*, *j*)*Δ* is set to the average of the potential values\n",
"at the four nearest-neighbor points.\n",
"\n",
"As an example of **domain decomposition**, consider the solution of a\n",
"partial differential equation by a finite difference method. It is known\n",
"from classical electrodynamics that the electric potential *U*(**x**) in\n",
"a charge free region of 2-D space satisfies *Laplace’s equation* (fully\n",
"discussed in § 19.4 ):\n",
"\n",
"$$\\tag*{10.17}\n",
" \\frac{\\partial^2 U(x,y)}{\\partial x^2}+ \\frac{\\partial^2\n",
"U(x,y)}{\\partial y^2 } = 0.$$\n",
"\n",
"We see that the potential depends simultaneously on *x* and *y*, which\n",
"is what makes it a partial differential equation. The electric charges,\n",
"which are the source of the field, enter indirectly by specifying the\n",
"potential values on some boundaries or charged objects.\n",
"\n",
"As shown in Figure 10.11, we look for a solution on a lattice of\n",
"(*x*, *y*) values separated by finite difference *Δ* in each dimension\n",
"and specified by discrete locations on the lattice:\n",
"\n",
"$$\\tag*{10.18} x = x_0 + i \\Delta, \\quad y = y_0 + j \\Delta, \\quad i,j=0,\\ldots,\n",
"N_{max-1}.$$\n",
"\n",
"When the finite difference expressions for the derivatives are\n",
"substituted into (10.17), and the equation is rearranged, we obtain the\n",
"finite-difference algorithm for the solution of Laplace’s equation:\n",
"\n",
"$$\\tag*{10.19}\n",
" U_{i,j}=\\frac{1}{4}\\left[U_{i+1,j}+U_{i-1,j}\n",
"+U_{i,j+1}+ U_{i,j-1} \\right ] .$$\n",
"\n",
"This equation says that when we have a proper solution, it will be the\n",
"average of the potential at the four nearest neighbors (Figure 10.11).\n",
"As an algorithm, (10.18) does not provide a direct solution to Laplace’s\n",
"equation but rather must be repeated many times to converge upon the\n",
"solution. We start with an initial guess for the potential, improve it\n",
"by sweeping through all space, taking the average over nearest neighbors\n",
"at each node, and keep repeating the process until the solution no\n",
"longer changes to some level of precision or until failure is evident.\n",
"When converged, the initial guess is said to have *relaxed* into the\n",
"solution.\n",
"\n",
"In Listing 10.1 we have a serial code `laplace.c` that solves the\n",
"Laplace equation in two dimensions for a straight wire kept at 100 V in\n",
"a grounded box, using the relaxation algorithm (10.18). There are five\n",
"basic elements of the code:\n",
"\n",
"1. Initialize the potential values on the lattice.\n",
"\n",
"2. Provide an initial guess for the potential, in this case *U* = 0\n",
" except for the wire at 100V.\n",
"\n",
"3. Maintain the boundary values and the source term values of the\n",
" potential at all times.\n",
"\n",
"4. Iterate the solution until convergence \\[(10.18) being satisfied to\n",
" some level of precision\\] is obtained.\n",
"\n",
"5. Output the potential in a form appropriate for 3-D plotting.\n",
"\n",
"As you can see, the code is a simple pedagogical example with its\n",
"essential structure being the array `p[40][40]` representing a (small)\n",
"regular lattice. Industrial strength applications might use much larger\n",
"lattices as well as adaptive meshes and hierarchical multigrid\n",
"techniques.\n",
"\n",
"When thinking of parallelizing this program, we note an algorithm being\n",
"applied to a space of data points, in which case we can divide the\n",
"domain into subspaces and assign each subspace to a different processor.\n",
"This is domain decomposition or data parallelism. In essence, we have\n",
"divided a large boundary-value problem into an equivalent set of smaller\n",
"boundary-value problems that eventually get fit back together. Often\n",
"extra storage is allocated on each processor to hold the data values\n",
"that get communicated from neighboring processors. These storage\n",
"locations are referred to as *ghost cells, ghost rows, ghost columns,\n",
"halo cells,* or *overlap areas*.\n",
"\n",
"Two points are essential in domain decomposition: 1) Load balancing is\n",
"critical, and is obtained here by having each domain contain the same\n",
"number of lattice points. 2) Communication among the processors should\n",
"be minimized because this is a slow process. Clearly the processors must\n",
"communicate to agree on the potential values at the domain boundaries,\n",
"except for those boundaries on the edge of the box that remain grounded\n",
"at 0 V. But because there are many more lattice sites that need\n",
"computing than there are boundaries, communication should not slow down\n",
"the computation severely for large lattices.\n",
"\n",
"To see an example of how this is carried out, the serial code\n",
"`poisson_1d.c` solves Laplace’s equation in 1-D, and\n",
"`poisson_parallel_1d.c` solves the same 1-D equation in parallel (codes\n",
"courtesy of Michel Vallieres). This code uses an accelerated version of\n",
"the iteration algorithm using the parameter *Ω*, a separate method for\n",
"domain decomposition, as well as ghost cells to communicate the\n",
"boundaries.\n",
"\n",
"**Listing 10.1 laplace.c** Serial solution of Laplace’s equation using\n",
"a finite difference technique.\n",
"\n",
" /* laplace.c: Solve Laplace equation with finite differences */\n",
"\n",
" #include \n",
" #define max 40 /* number of grid points */\n",
" main()\n",
" {\n",
" double x, p[max][max];\n",
" int i, j, iter, y;\n",
" FILE *output; /* save data in laplace.dat */\n",
" output = fopen(\"laplace.dat\",\"w\");\n",
" for(i=0; i\n",
"\n",
"1. Get the serial version of either `laplace.c` or `laplace.f` running.\n",
"\n",
"2. Increase the lattice size to 1000 and determine the CPU time\n",
" required for convergence to six places. Make sure that this is the\n",
" actual run time and does not include any system time. (You can get\n",
" this type of information, depending upon the operating system, by\n",
" inserting timer calls in your program.)\n",
"\n",
"3. Decompose the domain into four subdomains and get an MPI version of\n",
" the code running on four compute nodes. \\[Recall, we give an example\n",
" of how to do this in the `Codes` directory with the serial code\n",
" `poisson_1d.c` and its MPI implementation, `poisson_parallel_1d.c`\n",
" (courtesy of Michel Vallières).\\]\n",
"\n",
"4. Convert the serial code to three dimensions. This makes the\n",
" application more realistic, but also more complicated. Describe the\n",
" changes you have had to make.\n",
"\n",
"5. Decompose the 3-D domain into four subdomains and get an MPI version\n",
" of the code running on four compute nodes. This can be quite a bit\n",
" more complicated than the 2-D problem.\n",
"\n",
"6. Conduct a weak scaling test for the 2-D or 3-D code.\n",
"\n",
"7. Conduct a strong scaling test for the 2-D or 3-D code.\n",
"\n",
"\n",
"\n",
" **Figure 10.12** *(a)* A 3-D torus\n",
"connecting 2 × 2 × 2 compute nodes. *(b)* The global collective memory\n",
"system. *(c)* The control and Gb-Ethernet memory system (from \\[Gara et\n",
"al.(05)\\]).\n",
"\n",
"## 10.15 Example: IBM Blue Gene Supercomputers\n",
"\n",
"Whatever figures we give to describe the latest supercomputer will be\n",
"obsolete by the time you read them. Nevertheless, for the sake of\n",
"completeness, and to set the present scale, we do it anyway. At the time\n",
"of this writing one of the fastest computer is the IBM Blue Gene/Q\n",
"member of the Blue Gene series. In its largest version, its 96 racks\n",
"contains 98,304 compute nodes with 1.6 million processor cores and 1.6\n",
"PB of memory \\[Gara et al.(05)\\]. In June 2012 it reached a peak speed\n",
"of 20.1 PFLOPS.\n",
"\n",
"The name Blue Gene reflects the computer’s origin in gene research,\n",
"although Blue Genes are now general-purpose supercomputers. In many ways\n",
"these are computers built by committee, with compromises made in order\n",
"to balance cost, cooling, computing speed, use of existing technologies,\n",
"communication speed, and so forth. As a case in point, the compute chip\n",
"has 18 cores, with 16 for computing, one to assist the operating system\n",
"with communication, and one as a redundant spare in case one of the\n",
"others was damaged. Having communication on the chip reflects the\n",
"importance of communication for distributed-memory computing (there are\n",
"both on- and off-chip distributed memories). And while the CPU is fast\n",
"with 204.8 GFLOPS at 1.6 GHz, there are faster ones made, but they would\n",
"generate so much heat that it would not be possible to obtain the\n",
"extreme scalability up to 98,304 compute nodes. So with the high\n",
"efficiency figure of 2.1 GFLOPS/watt, Blue Gene is considered a\n",
"“green”computer.\n",
"\n",
"We look more closely now at one of the original Blue Genes, for which we\n",
"were able to obtain illuminating figures \\[Gara et al.(05)\\]. Consider\n",
"the building-block view in Figure 10.11. We see multiple cores on a\n",
"chip, multiple chips on a card, multiple cards on a board, multiple\n",
"boards in a cabinet, and multiple cabinets in an installation. Each\n",
"processor runs a Linux operating system (imagine what the cost in both\n",
"time and money would be for Windows!) and utilizes the hardware by\n",
"running a distributed memory MPI with C, C++, and Fortran90 compilers.\n",
"\n",
"\n",
"\n",
" **Figure 10.13** The single-node memory\n",
"system (as presented by \\[Gara et al.(05)\\]).\n",
"\n",
"Blue Gene has three separate communication networks (Figure 10.12).At\n",
"the heart of the network is a 3-D torus that connects all the nodes. For\n",
"example, Figure 10.12 A shows a sample torus of 2 × 2 × 2 nodes. The\n",
"links are made by special link chips that also compute; they provide\n",
"both direct neighbor-neighbor communications as well as cut-through\n",
"communication across the network. The result of this sophisticated\n",
"communications network is that there is approximately the same effective\n",
"bandwidth and latencies (response times) between all nodes. However, the\n",
"bandwidth may be affected by interference among messages, with the\n",
"actual latency also depending on the number of *hops* to get from one\n",
"node to another\\[*Note:* The number of hops is the number of devices a\n",
"given data packet passes through.\\] A rate of 1.4 Gb/s is obtained for\n",
"node-to-node communication. The collective network in Figure 10.12 B is\n",
"used for collective communications among processors, such as a\n",
"*broadcast*. Finally, the control and gigabit ethernet network\n",
"(Figure 10.12 C) is used for I/O to communicate with the switch (the\n",
"hardware communication center) and with ethernet devices.\n",
"\n",
"The computing heart of Blue Gene is its integrated circuit and the\n",
"associated memory system (Figure 10.13). This is essentially an entire\n",
"computer system on a chip, with the exact specifications depending upon\n",
"the model, and changing with time.\n",
"\n",
"\n",
"\n",
"**Figure 10.14** A schematic of an exascale computer in which, in addition to\n",
"each chip having multiple cores, a graphical processing unit is attached to each\n",
"chip. (Adapted from\n",
"\\[Dongarra(11)\\].)\n",
"\n",
"## 10.16 Exascale Computing via Multinode-Multicore-GPU’s\n",
"\n",
"The current architecture of top-end supercomputers (Figure 10.14) uses a\n",
"very large numbers of nodes, with each node containing a chip set that\n",
"includes multiple cores as well as a graphical processing unit (GPU)\n",
"attached to the chip set\\[*Note:* GPU’s and their programming are\n",
"discussed in [Chapter 11, *Applied HPC: Optimization, Tuning & GPU\n",
"Programming*](CP111.ipynb).\\]. In the near future we expect to see\n",
"laptop computers capable of teraflops (1012 floating-point\n",
"operations per second), deskside computers capable of petaflops, and\n",
"supercomputers at the exascale, in terms of both flops and memory,\n",
"probably with millions of nodes.\n",
"\n",
"Look again at the schematic in Figure 10.14. As in Blue Gene, there\n",
"really are large numbers of chip boards and large numbers of cabinets.\n",
"Here we show just one node and one cabinet and not the full number of\n",
"cores. The dashed line in Figure 10.14 represents communications, and it\n",
"is seen to permeate all components of the computer. Indeed,\n",
"communications have become such an essential part of modern\n",
"supercomputers, which may contain 100’s of 1000’s of CPU’s, that the\n",
"network interface “card” may be directly on the chip board. Because a\n",
"computer of this sort contains shared memory at the node level and\n",
"distributed memory at the cabinet or higher levels, programming for the\n",
"requisite data transfer among the multiple elements is a fundamental\n",
"challenge, with significant new investments likely to occur \\[Dongarra\n",
"et al.(14)\\].\n",
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 2",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.11"
}
},
"nbformat": 4,
"nbformat_minor": 0
}